Mapas del silencio: ¿Qué tan bien usan el Ministerio TIC de Colombia y sus (ex)funcionarios las TIC para comunicarse con los ciudadanos? El caso de Twitter
¿Qué es más demorado: un trino (tuit) o un derecho de petición para obtener una respuesta de entidades públicas y sus (ex)funcionarios? En esta entrada al blog lanzamos experimento público al respecto, usando como ejemplo intentos de comunicación establecidos con el Ministerio de las TIC de Colombia y sus (ex)funcionarios. Se emplean técnicas de extracción y visualización de datos con datos pequeños (small data) y se habla de cómo esto puede estar al alcance de más ciudadanos y ayudar a un diálogo más fluido entre gobierno, funcionarios y ciudadanos. Al final se mencionan algunas exploraciones, escritos y tentativas futuras que surgen de esta iniciativa.
La idea es crear un ciclo de realimentación positiva en el que podamos enviarle a distintas instituciones, funcionarios públicos y otras entidades, estas visualizaciones de datos, para ver si esto puede ayudarles a detectar asuntos importantes desatendidos o no contestados, de manera que puedan responderlos de maneras más incluyentes, abiertas y eficientes.
Experimento público y abierto: ¿Qué es más demorado: un trino (tuit) o un derecho de petición para obtener una respuesta de entidades públicas y sus (ex)funcionarios? A menudo escuchamos el discurso triunfalista de que las TIC puede mejorarlo casi todo (empresa, educación, trabajo, salud, gobierno, etc) de manera prácticamente automática con sólo introducirlas en los distintos contextos. Creo que es un discurso al que hay que aproximarse con una mirada crítica y sano exceptisismo, como lo han hecho figuras como Bill Gates, así como expertos en el tema de TIC para el cambio social, (un ejemplo se puede ver en libros como geek heresy), particularmente si uno se dedica al tema de las TIC. Si nos apegaramos a esa narrativas, uno esperaría que en esta época de vértigo e hiperconectividad, los trinos fueran la marca de la eficiencia y la rapidez, no sólo en el rumor cotidiano y el flujo de noticias, sino en la gestión pública, particularmente en el caso de las instituciones y funcionarios que impulsan las tecnologías digitales para lograr metas asociadas a la eficiencia. Muchas instituciones gubernalmentales tienen cuentas de twitter, así como los funcionarios y exfuncionarios públicos que están o estuvieron en ellas ocupando altos cargos directivos. Y a pesar de ese hecho, tanto instituciones como (ex)funcionarios parecieran estar permanentemente en un monólogo público, ejerciendo algo que parece ser comunicación y participación, pero que no tiene el caracter de doble vía esencial de los actos comunicativos. Ojalá nos equivoquemos y efectivamente la incorporación de las TIC establezca canales públicos y eficientes de comunicación en doble vía que permitan ejercer el diálogo, la deliberación, la toma de decisiones y veheduría ciudadana las mismas, sobre la función pública, los presupuestos nacionales y los dineros de todos, entre otros temas importantes.
Daré cuenta de un experimento abierto y público para respondernos la pregunta con la que iniciamos. El experimento es sencillo, usanto técnicas de extracción y visualización de datos, sobre pequeños datos siginificativos (small data [1]) y miramos qué tanto tardan sin responder los (ex)funcionarios e instituciones públicas y crearemos unos "mapas del silencio" para los mismos. Acá mostraremos el inicio de tales mapas del silencio. Luego tomaremos varias de las cosas a las que no contestaron o lo hicieron superficialmente y redactaremos un derecho de petición que use el comportamiento en línea auditable de tales entidades y funcionarios, para indagar sobre sus formas de presencia en línea (empezando con Twitter, pero yendo más allá a sitios web y presupuestos de contratación), como argumento a favor de prácticas más eficientes, transparentes y empoderadoras de la ciudadanía. Enviaremos los mapas de silencio a los (ex)funcionarios e instituciones vía Twitter para ver si efectivamente contestan o cambian sus silencios y, con algo de éxito, estos ciclos de realimentación iniciaran formas de diálogo distintas entre (ex)funcionarios, instituciones y ciudadanía. Todo ocurrirá con de manera abierta y auditable, que hagan trazable la información que acá se presenta y la forma como se trata ésta (algoritmos, datasets, documentos de soporte, interfaces, etc), usando software libre, datos abiertos y públicos y repositorios de código
El experimento
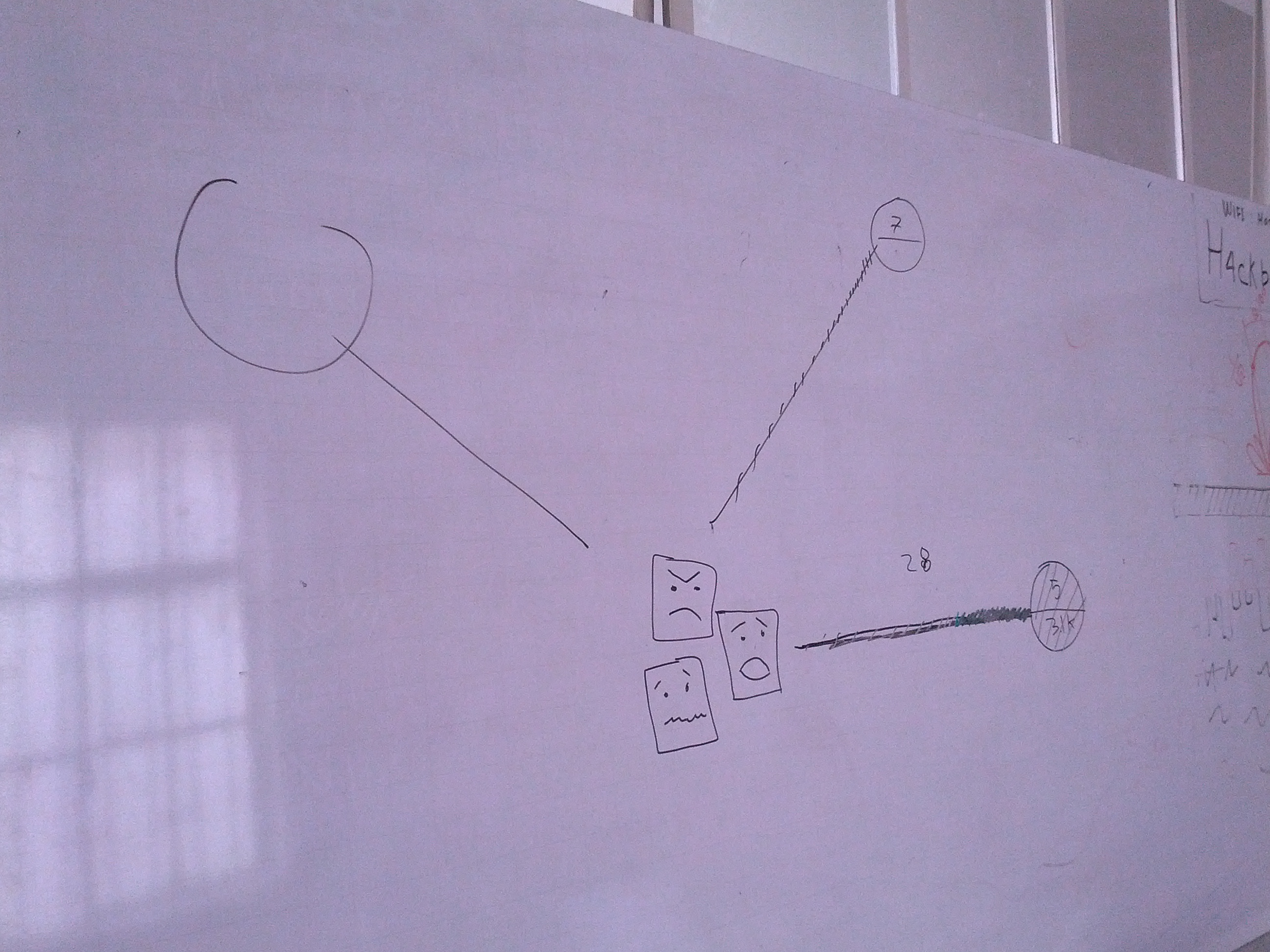
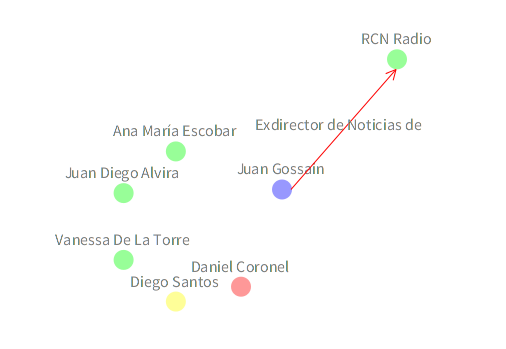
El experimento se concretó, hace poco, en la última semana de junio, durante el primer Dataweek, que en sí mismo dejó un muy buen balance (aunque eso sería motivo de otras publicaciones, como las memorias en la página web y la respectiva nota al pie [2] ). Pasamos, en casi una semana, de la imagen garabateada a mano que ven a la izquierda al prototipo preliminar a la derecha, que no sólo es una imagen hecha en computador, sino un algoritmo completo de extracción y visualización de información para Twitter, escrito, de manera colectiva, en grafoscopio.













{kind=link}