¿Cómo sería una semana del código co-organizada desde la sociedad civil?, ¿una que no sólo caiga en el lugar común del "Hola mundo!" y el video juego?¿Cómo sería una semana donde los espacios públicos, como las bibliotecas, reconozcan a comunidades tecnológicas de base locales y preexistentes, en lugar de ser sólo plataformas para el posicionamiento de empresas privadas? Esta entrada en un exploración a esas preguntas desde acciones concretas que ocurrirán esta semana y se conectan con lo que se hace desde las comunidades de base en Colombia.
Con el hash tag #YoPuedoProgramar, Microsoft, en asocio con las bibliotecas públicas, lanzó hoy 3 de octubre su campaña, para aproximar a las personas al mundo de la programación. Me parece que las bibliotecas públicas deberían ser un espacio más que apropiado para ello, pero, como he venido diciendo desde el 2013, me preocupa que las infraestructuras y recursos públicos y temas de la cultura del código, como las hackatones, sean usados, de manera sistemática, para el beneficio y posicionamiento prioritario de las entidades privadas, en este caso Microsoft, invisibilizando de nuevo a la sociedad civil y las comunidades de base tecnológicas presentes en el país.
Así que decidí empezar mi propia semana del código, en continuidad y conexión con otras semanas que hemos venido realizando, desde comunidades y espacio de base, con un enfoque de alfabetización crítica de código y datos (critical data & code literacy), como el Data Week. La idea es mostrar eso que, tanto desde Microsoft como desde las instituciones públicas, esta semana invisibiliza desafortunadamente: que existen diversas apuestas, comunidades, tecnologías, enfoques y edades para aproximarse al código y que algunas de ellas, intentan un enfoque crítico, que por ejemplo no empieza por el fatigado y poco significativo: "Hola mundo!".
Precisamente en aras de mostrar aquella continuidad con lo que ya se ha estado haciendo, he etiquetado este evento como el #DataWeek6, para conectarlo con las ediciones previas que hemos realizado: cinco desde HackBo y una desde el Colaboratorio de Medellin. Los tuits tendrán por tanto las etiquetas #DataWeek6 y #YoPuedoProgramar, para poder rastrearlas en el contexto de las que visiblizan Microsoft y las bibliotecas y otras entidades públicas, así como los funcionarios. Me parece particularmente interesante ver los mensajes a los que dichas bibliotecas, espacios, instituciones y funcionarios públicos harán eco, retrinándolos, contestándoles, citándolos y comparar las fuentes (ejp: ¿son ellas ciudadanas o son privadas?) y creo que nuestro proyecto de los data selfies está particularmente adaptado para ello.
La dinámica es sencilla: Iré a una biblioteca cercana a donde me encuentre, un par de horas al día y llevaré un diario de lo que vaya ocurriendo. Como algunas bibliotecas no tienen muy buena conectividad (o ninguna), y como algunas no están enteredas de la semana del código o de la iniciativa #YoPuedoProgramar, algunos días el trabajo será fuera de línea, y sincronizaré lo que haya hecho en mi portátil, con repositorios de código y lo compartiré al final de ese día o a comienzos del siguiente con los hashtags ya indicados y algunas capturas de pantalla de los repositorios de código y de las interfaces. Los sistemas actuales de gestión de código (como Fossil y Monticello [1],[2]), soportan trabajo fuera de línea 100% y se adecuan a la realidad nacional de lugares como las bibliotecas.
La intensión es trabajar en temas pedagógicos, en la medida en que el contexto lo permita. Por ejemplo, si hay buenas condiciones de sonido y buena conectividad para crear y subir un videocast, haré experimentos mostrando las nuevas caracterísitcas de Grafoscopio. También trabajaré en temas que requieren mayor experticia y que mejoran la infraestructura de aquello que está de cara al aprendiz y le permiten el desarrollo de esta alfabetización crítica en datos y código, particularmente cuando yo esté sólo o no haya tan buena conectividad y en aras de conectar ese trabajo previo con lo que ocurrirá esta semana, pues, en muchas ocasiones, crear buenos entornos de aprendizaje para novatos implica ocuparse de la infraestructura y lo invisible.
Dia 1: Hello Cajicá
Inicio la semana del código en la nueva biblioteca de Cajicá, el municipio donde viví buena parte de mi infancia y adolecencia y me inicipe como ratón de biblioteca. El nuevo edificio es mucho más iluminado y espacioso, pero su tamaño contrasta con lo vacio que se encuentra. Acá no hay semana del código, no hay nadie que parezca estar dedicado a ella, y me dijeron al entrar, que la señal de Internet se demora cerca de un mes, mientras se surte la licitación.
— "Es decir que inauguron la biblioteca sin Internet?", pregunto yo.
— "Si señor", contesta la bibliotecaria.
— "Disculpa, ¿tu sabes algo de la iniciativa 'Semana del código' o 'Yo puedo programar'?
— "No ¿En qué consisten?" y yo le explico brevemente.
Pensaba leer y anotar algunas cosas en línea, usando hypothesis, sobre la Biblioteca como infraestructura y los peligros de su enagenamiento por la lógica del Silicon Valley, recomendadas por Carlos en nuestra lista, y muy apropiadas con motivo de este evento, bajo la idea de alfabetización crítica en datos y código (critical code & data literacy). Como no hay conectividad empecé escribiendo en esta libreta de Grafoscopio y la agregué al repositorio de fossil del data week.
Lo siguiente que haré será trabajar con datos que he descargado y que están fuera de línea para el proyecto de los data selfies. Quiero arreglar un par de bugs.
Para finalizar algunas imágenes que ilustran este primer día:

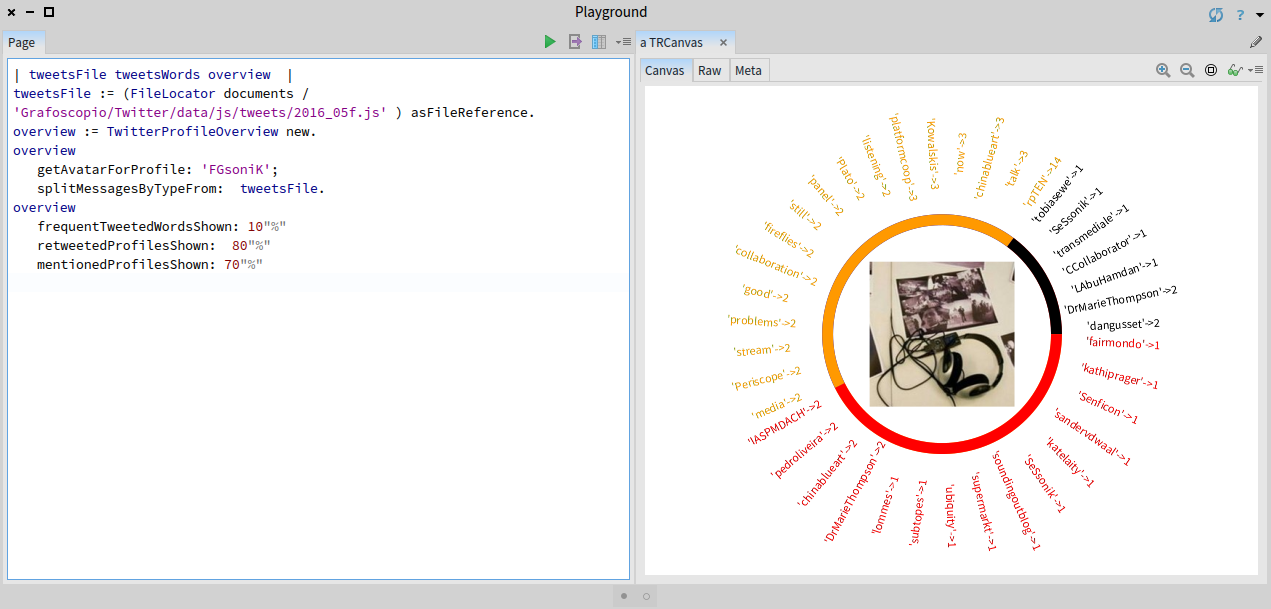

Dia 2: Hello MinTIC y Microsoft, vía Twitter
Hoy me dediqué a organizar, con la conectividad y la doble pantalla, en mi apartamento en Bogotá, aquello que inicié ayer en Cajicá sin conectividad. Hice unos trinos al repecto y escribí a la lista de correo de la comunidad de Grafoscopio. Como la idea es hacer un #DataWeek6 ágil, que no tome más de un par de horas al día, hoy no voy a ir a ninguna biblioteca pública, pues ya invertí ese tiempo diario desde mi apartamento. Pero mañana regreso a las bibliotecas públicas. ¿Alguna recomendación de una biblioteca cercana a Chapinero o Teusaquillo para continuar el resto de la semana?
Acá están los trinos que ilustran el día:
@lunadavid @Microsoft @Ministerio_TIC Iniciamos también un #YoPuedoProgramar #DataWeek6 desde la #SociedadCivil: https://t.co/8lPVYKEm4O pic.twitter.com/qUDTTitMGO
— Offray Vladimir Luna (@offrayLC) 4 de octubre de 2016
@lunadavid @Ministerio_TIC @AlcaldiadeMed @Educacionbogota @RutaQAlcaldia @ColombiaJoven Apoyarían este https://t.co/8lPVYKEm4O ? pic.twitter.com/23ETdGhTi3
— Offray Vladimir Luna (@offrayLC) 4 de octubre de 2016
Dia 3: Enchulando el entorno y marcha por la paz
Hoy es la marcha por la paz en la tarde. Con conflicto o postconflicto este país y el mundo necesita de nosotros y hay que empujarlo del primero al segundo. Como se trata de mostrar una aproximación crítica al código y los datos, no tiene sentido que uno se abstraiga del mundo programando, mientras él sigue girando. Por eso la sesión de hoy fue corta (cerca de una hora) y en mi casa: básicamente depuré un script para cambiar el papel tapiz de mi entorno Pharo, lo cual además del placer visual, brinda un conjunto de colores más armónicos y menos brillantes, que al ayudan a conciliar el sueño, sobre todo si uno está frente al monitor en horas de la noche. Puede sonar new age, pero tiene que ver en realidad con cómo ciertas frecuencias de luz afectan la producción de melanina y cómo esta afecta el sueño. Lo he comprobado en persona con papeles tapiz claros y oscuros de mi entorno de computo/programación.
Como mi pantalla secundaria es ultra wide screen, aprendí que un factor clave en la búsqueda, que no había tenido en cuenta antes, es colocar el parámetro "21:9" que dará fondos de escritorio (backgrounds) en resoluciones que funcionan bien para esta proporción.
Acá están los resultados:
El script (click acá para esta ver esta versión desde el "pastebin" de Pharo y acá para otra con más papeles tapiz):
| backgrounds |
"Nice images to choose from"
backgrounds := Dictionary new.
backgrounds :=
{'pharo' -> 'http://orig09.deviantart.net/6eb6/f/2016/161/1/f/omnos_the_black_sky_noir_style_hdr_wallpaper_by_charlie_henson-da5oxs0.png'.
'portal' -> 'http://orig13.deviantart.net/e8d3/f/2013/092/a/3/glados_s_activation_by_first9-d605rwi.jpg'.
'dock' -> 'http://www.fullhdwpp.com/wp-content/uploads/Impressive-Clouds-over-the-Dock_www.FullHDWpp.com_www.FullHDWpp.com_.jpg'.
'xenoblade' ->'http://i.imgur.com/3sQDIg3.jpg'.
'storm' -> 'https://i.redd.it/w9ilib62tzox.jpg'.
'montains' -> 'http://i.imgur.com/ZnxcmpK.jpg'.
'spaceStation' -> 'http://i.imgur.com/b47JMKE.jpg'.
'eathGlowing' -> 'http://i.imgur.com/dlhR7nY.jpg'.
'ship49' -> 'http://i.imgur.com/aQ2uZfV.jpg'.
'2001' -> 'http://i.imgur.com/Fp0GWRP.jpg' } asDictionary.
World
backgroundImage: (ImageReadWriter formFromStream:
(ZnEasy get: (backgrounds at: '2001') ) contents readStream)
layout: #center.La captura de pantalla:
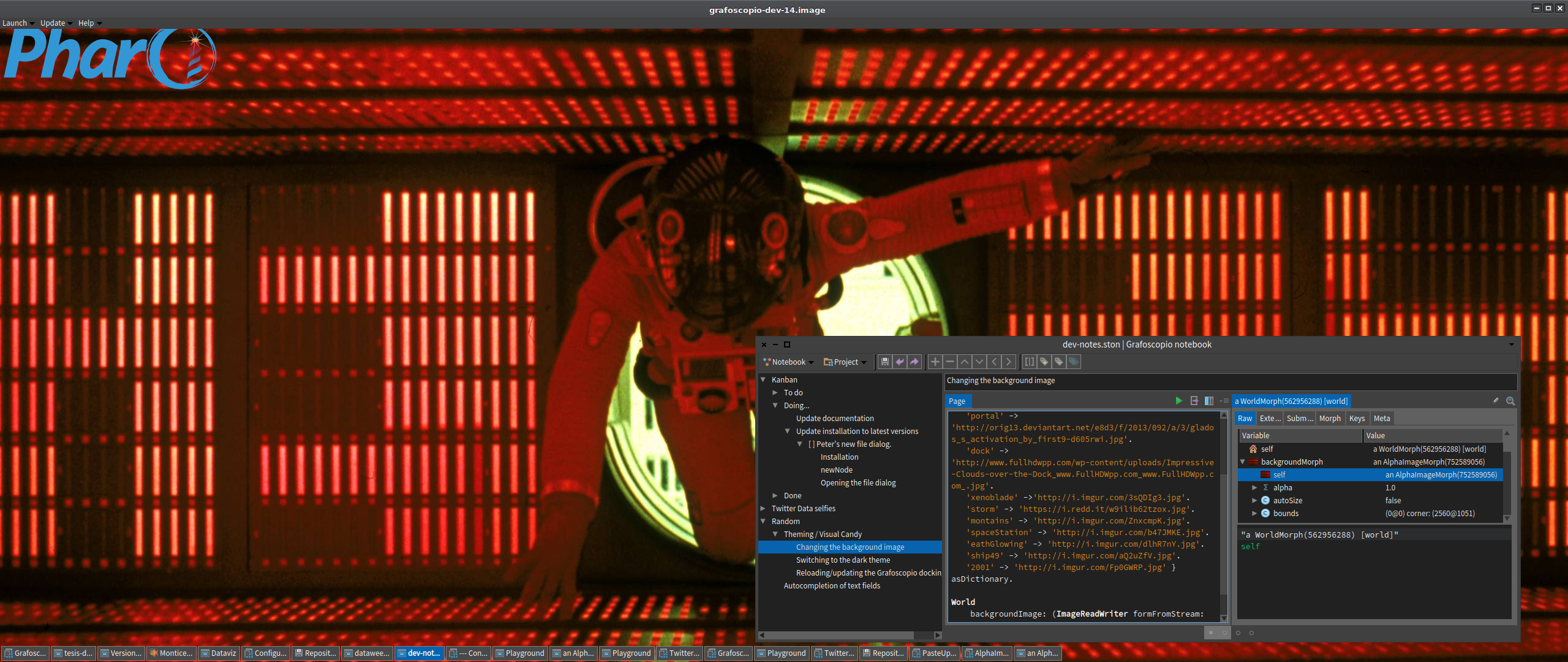
Los tuits:
"I can give you my complete assurance [the] work [of cinema @hackbo] will back to normal" cc: @LaParCreacion #DataWeek6 #YoPuedoProgramar pic.twitter.com/URfIwKKCe9
— Offray Vladimir Luna (@offrayLC) 5 de octubre de 2016
Actualizado el #día3 del #DataWeek6 durante la jornada #yopuedoprogramar: https://t.co/8lPVYKEm4O pic.twitter.com/YAc0U9xRan
— Offray Vladimir Luna (@offrayLC) 5 de octubre de 2016
Hasta la marcha hoy en la tarde en Bogotá. El encuentro es a las 4:00 pm de la Javeriana y a las 5:00 en la plaza de Bolivar. Ojalá puedan asistir a los encuentros en otras ciudades.
Día 4: Recuperando código perdido
Hoy también fue un día corto y fuera de las bibliotecas. Creo que ese tipo de cosas son inevitables cuando la vida, contingente, se cruza con las semanas de código. Intentaré volver a las bibliotecas públicas en los últimos días del evento, pero no sé cuánto logre. Al menos mantener los post diarios, con las pequeñas cosas que ocurren para mejorar la infrasestructura de Grafoscopio mientras estoy trabajo en solitario es una propósito que se ha cumplido y que seguramente ayudará a aprendices que se aproximen al código desde esta perspectiva crítica y con estas herramientas a hacerlo de maneras más fluidas.
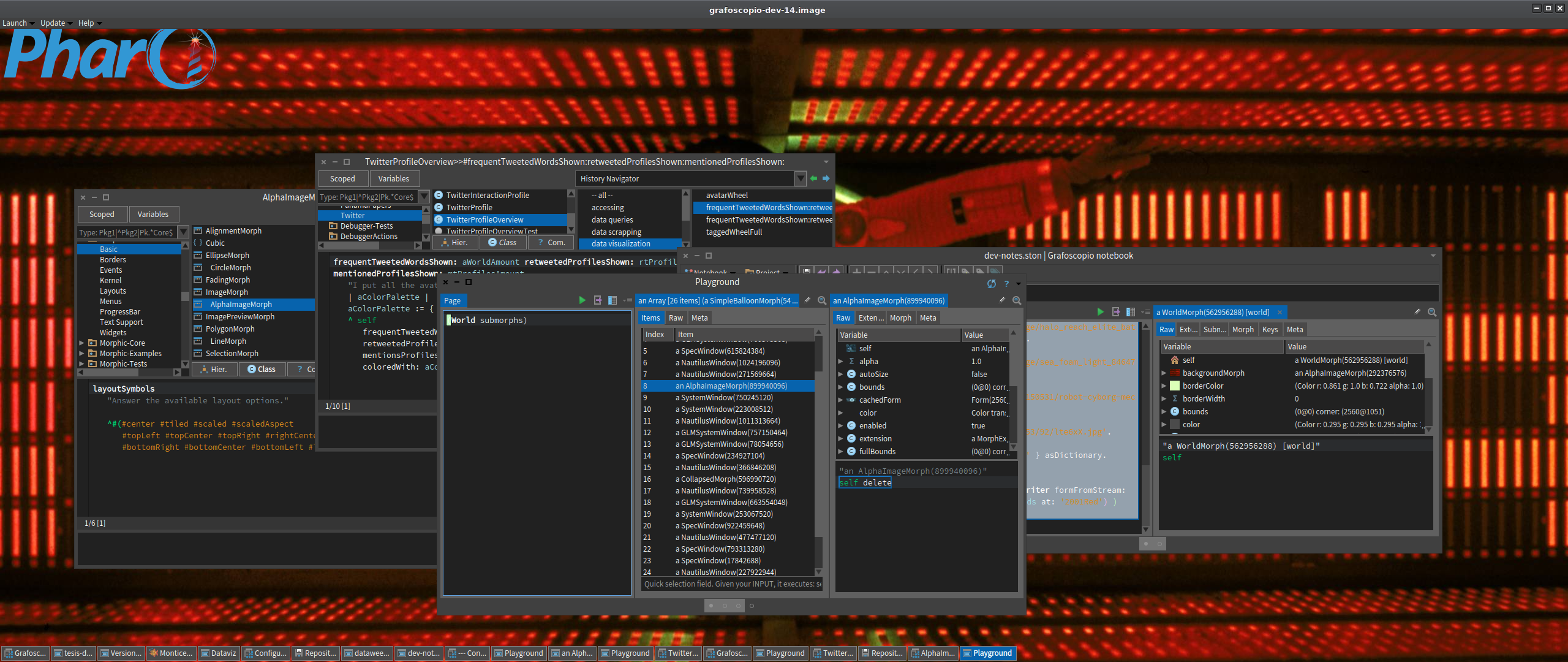
Mi "momento del código" de hoy (de menos de una hora, incluido este blog post) lo invertí en recuperar un cambio perdido en el #DataWeek5 pues sobre escribí desde una imagen, lo que había hecho con otra. Afortunadamente la gestión de código y su historial viene integrado en Pharo. Bastó un video del MOOC de Pharo para recordar como recuperar estos cambios.
A continuación unas capturas de esta recuperación con pies de páginas explicativos.
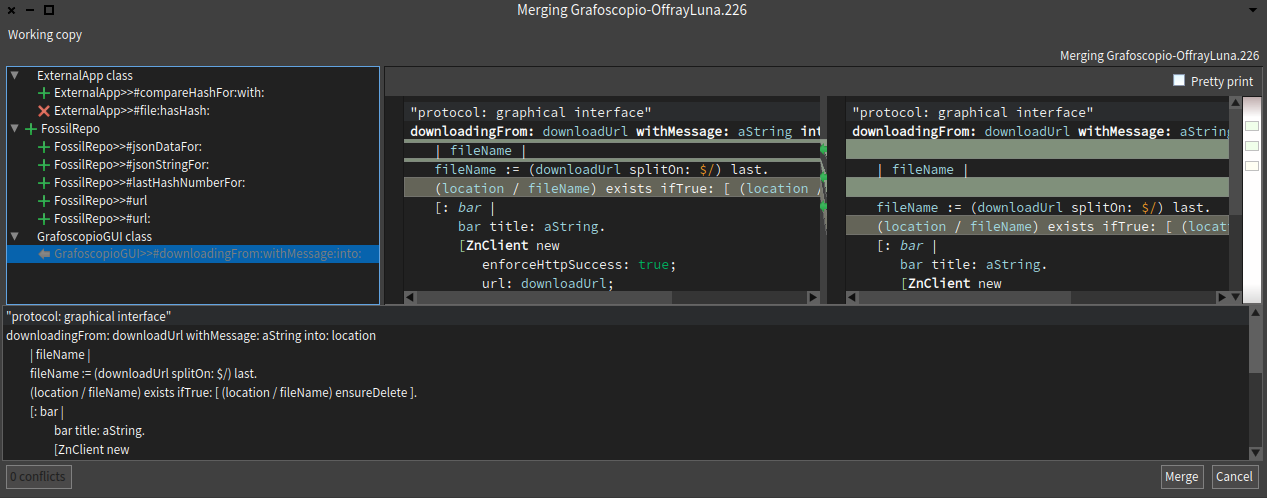
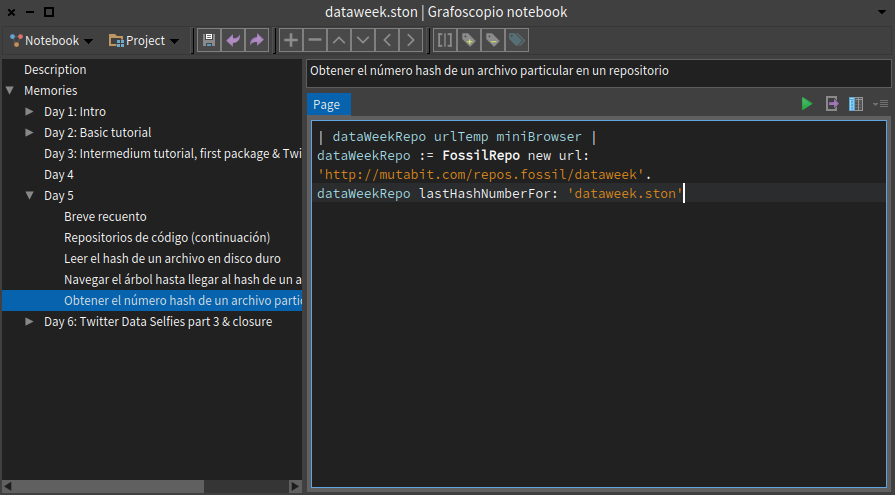
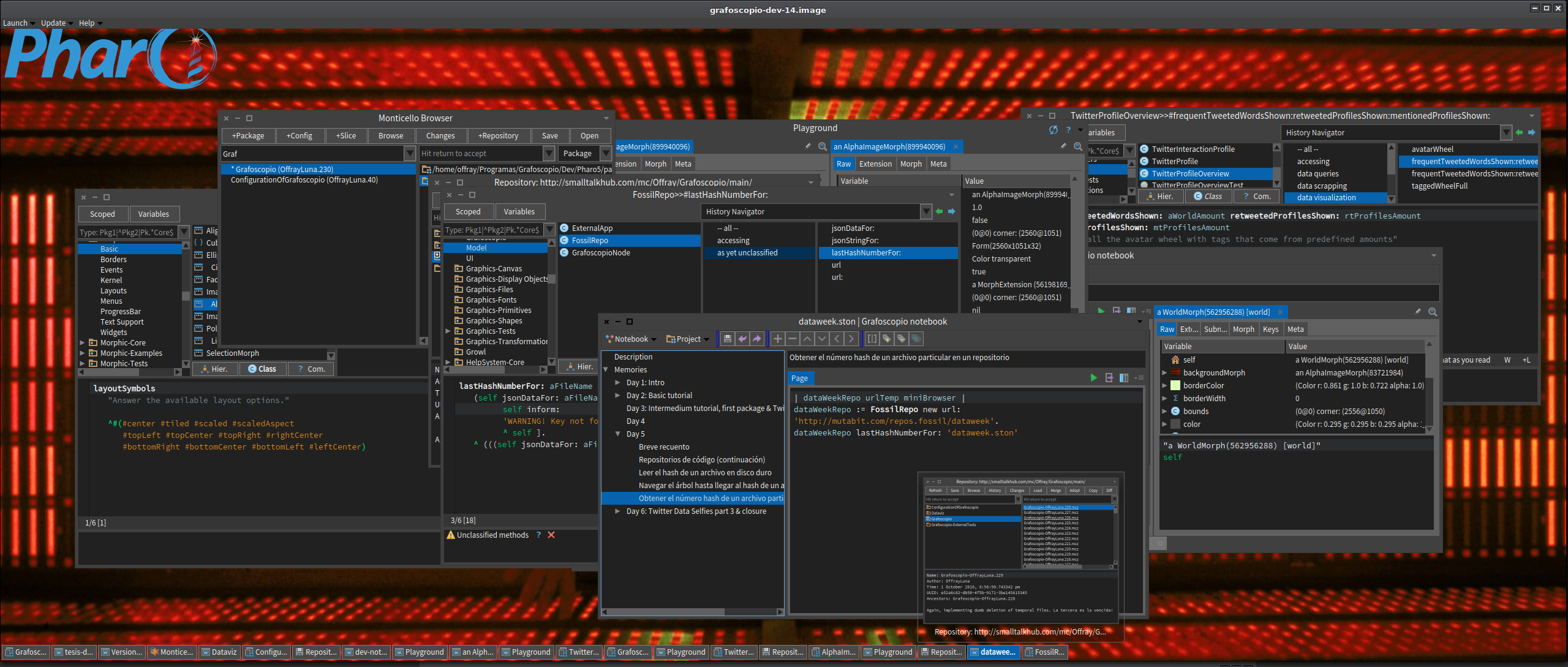
Día 5: Refactoring
Programé en casa otra vez, por andar dedicado a asuntos de la tesis doctoral, lo cual estuvo bien y es una muestra de lo contingente de nuevo. Hacer código se cruza con la vida: en ocasiones es parte de ella, en otras hay que sacarle un tiempo extra, particularmente, cuando hay esta desarticulación entre comunidades de base, por un lado, y, por otra, el estado y/o los privados. Como van las cosas creo que la idea de ir cada día a una biblioteca, será más bien una cosa que ocura eventualmente, más que una dinámica propia de cada día. Aún así me parece una buena dinámica para futuras ediciones.
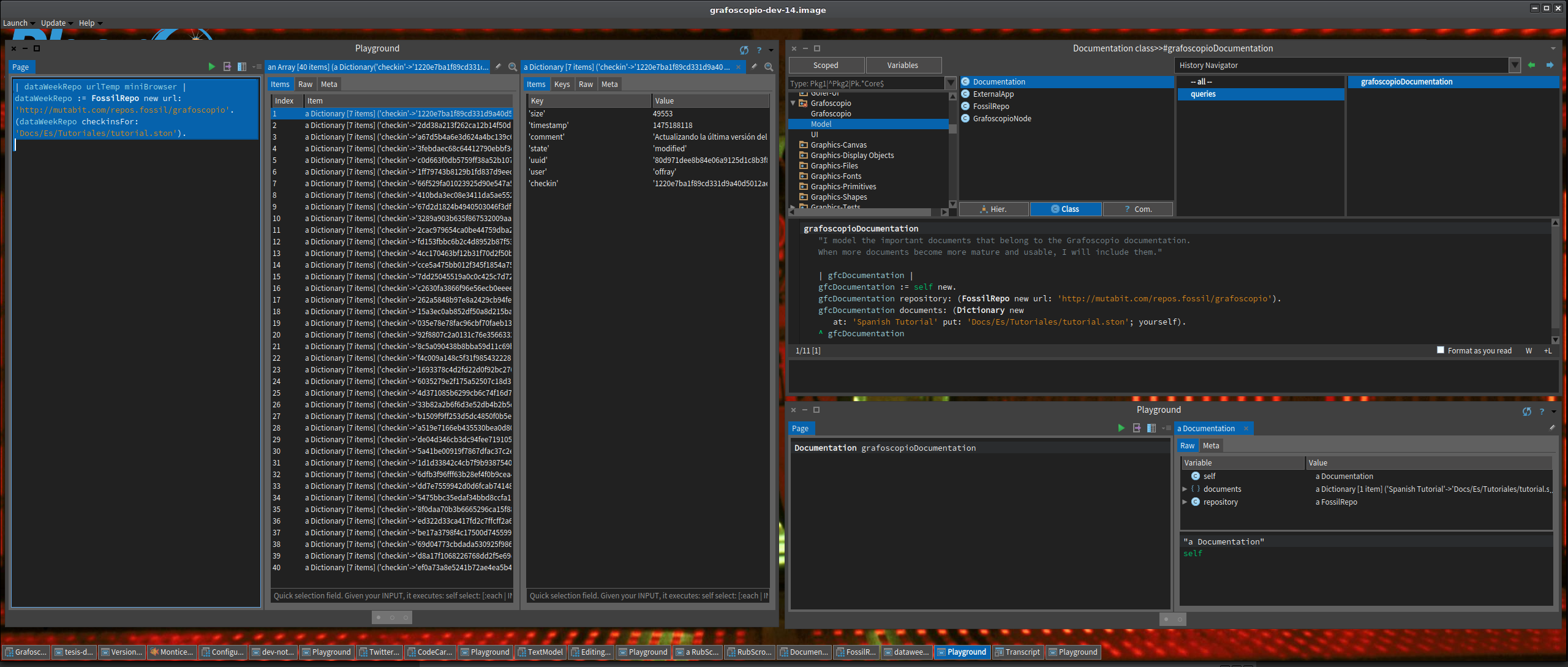
De nuevo me ocupé de la infraestructura, que mejorará a Grafoscopio para futuros aprendices. Esencialmente hice refactoring de código, así el método que consultaba el código de integridad para la última versión de un archivo (hash), fue rehecho para que dependa de un método que puede consultar toda la historia de un archivo (véase la gráfica inferior a la derecha). Como ahora tenemos un objeto que modela los repositorios de Fossil (gracias al Data Week 5), empecé a rehacer la manera en que manejamos la documentación, y si bien se podría diseñar mejor, el actual diseño va a mejorar y eliminar mucho código desordenado que modelaba la documentación previa, usando diccionarios en lugar de repositorios de fossil. Esto a su vez traerá un sistema de instalación mucho más limpio e integrado, que permitirá instalar el software y su documentación en un sólo paso, en lugar de hacerlo separandamente. Es hacia donde me inclino a trabajar en los días restantes.
La captura de pantalla de abajo muestra en tres ventanas el refactoring de hoy:
Día 6: Más refactoring
Rehacer código es inevitable y cuando se hace bien, el código complicado y largo es reemplazado por menos código que hace lo mismo y mejor, con lo cual los sistemas informáticos decrecen en complejidad accidental (complicación) e intentan crecer sólo en la complejidad esencial. En el caso de Smalltalk, el entorno dinámico soporta la reescritura de código de maneras muy fluidas y cuando uno está aprendiendo y aclarando el problema, es habitual pasar de pocos objetos con métodos monolíticos y confusos a más objetos con métodos modulares y claros. Hoy mostraré dos ejemplos ilustrados de eso, vía capturas de pantalla. A la izquierda estará el código viejo y a la derecha el código refactorizado. Después de cada par de imágenes se explican algunos detalles.
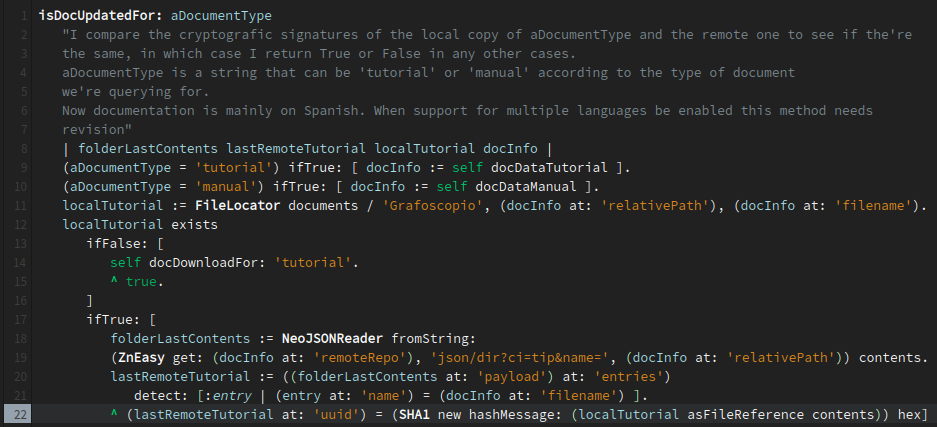

El par de imágenes anteriores corresponden al código de GrafoscopioGUI class>>isDocUpdatedFor
y de GrafoscopioDocumentation class>>isUpdatedFor:,
que permiten saber si un documento particular está actualizado antes
y después de refactoring, con 22 y 8 líneas de código (incluidos comentarios).
En este caso, los comentarios y código más largos, a la derecha, indican un código que deber ser
explicado más detalladamente para hacer sentido de convenciones que no son evidentes para el lector,
y guardadas en diccionarios y sin la asistencia de objetos específicos para modelar el problema.
A la izquierda, comentarios y código cortos, son logrados gracias a la implementación y uso de
objetos específicos como FossilRepo y GrafoscopioDocumentation, que contienen más conocimiento
del dominio del problema, creando mayor legibilidad y modularidad.
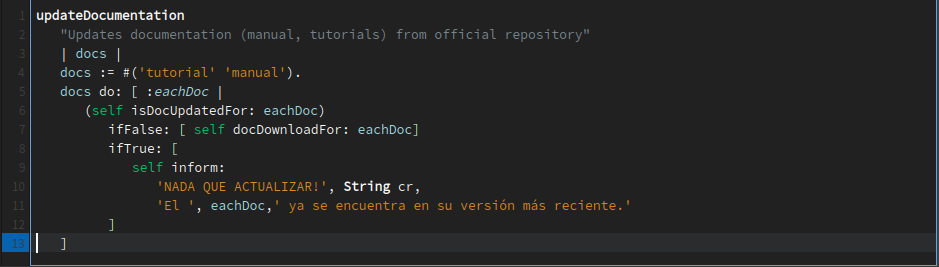

El par de imágenes anteriores corresponden al código de GrafoscopioGUI class>>updateDocumentation
y de GrafoscopioDocumentation class>>isUpdated:,
que permiten saber si todos los documentos están actualizados.
El código de la derecha no es modular, y la actualización también se encarga de consultar si
los documentos están al día (lo cual deberían ser funciones distintas).
El código de la izquierda se ocupa de una sóla cosa (mirar si los documentos están al día) y
podría ser usada por otros mensajes (módulares), incluyendo el de actualizar la documentación.
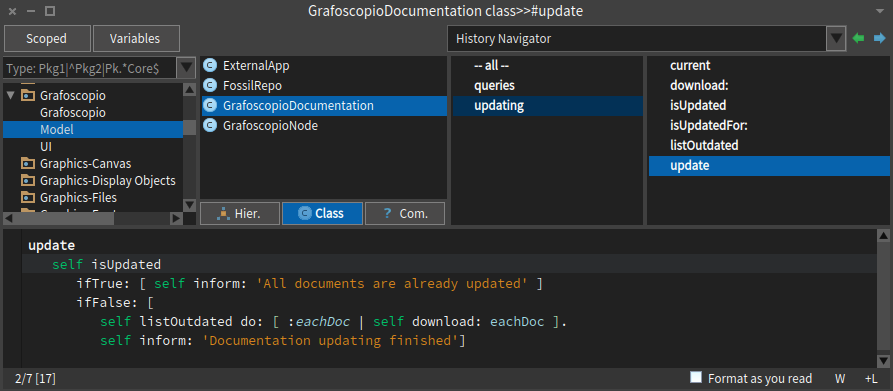
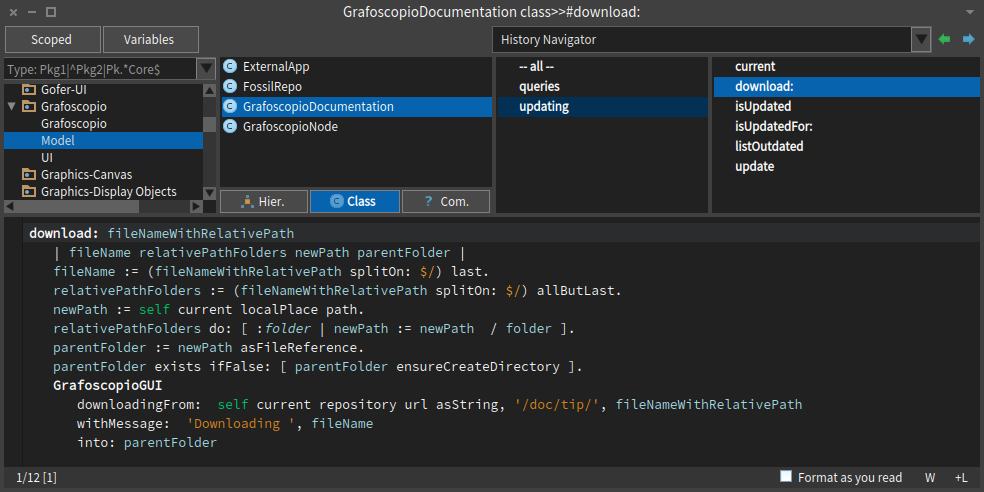
Día 7: Actualizar la documentación de Grafoscopio
La sesión de hoy del #DataWeek6 con motivo de la semana del código y la campaña #YoPuedoProgramar estuvo centrada en mejorar la forma en que se instala y actualiza la documentación de Grafoscopio. Este trabajo se centra en dos pequeños métodos, mostrados en las capturas de pantalla de abajo. Quedan algunas cosas por mejorar, por ejemplo, el procedimiento actual verifica si las copias locales difieren de las remotas y en caso tal, instala las remotas, pero realmente debería detectar, además, cuál es la más reciente manteniendo esta sobre las más antiguas o dándole al autor (usuario), la posibilidad de elegir.
Esta semana del código y edición sexta del Data Week, siguió incorporando cambios orgánicos e importantes que servirán en ediciones venideras del evento. Las mejoras serán parte de la preparación y ejecución de las siguientes ediciones del Data Week, continuando con la séptima edición, que haremos paralela al AbreLatam/Condatos, en las acostumbradas dos sesiones, del 27 al 29 de octubre y del 3 al 5 de noviembre.
Acá las capturas de pantalla del día de hoy:
Esto termina mi compromiso de programar y escribir cada día de la semana, mostrando acciones diversas que ya ocurren desde la sociedad civil respecto a herramientas, infraestructuras y prácticas que permiten aproximarse críticamente al código y los datos y hacer más plurales y potentes las voces ciudadanas.